Manage the Impala Connector
This applies to: Visual Data Discovery
The Symphony Cloudera Impala™ connector allows you to visualize huge volumes of data stored in their Hadoop cluster in real time and with no ETL. Symphony supports Impala versions 3.2 - 3.4.
Before you can establish a connection from Symphony to Cloudera Impala storage, a connector server needs to be installed and configured. See Manage Connectors and Connector Servers for general instructions and Connect to Impala for details specific to the Cloudera Impala connector.
After the connector has been set up, you can create data source configurations that specify the necessary connection information and identify the data you want to use. See Manage Visual Data Discovery Data Source Configurations for more information. After data sources are configured, they can be used to create dashboards and visuals from your data. See Create Data Discovery Dashboards.
This topic describes:
See also:
- Work with Distinct Counts on Cloudera Impala
- Enable Data Sharpening for Cloudera Impala Data Sources
Feature Support
Connector support for specific features is shown in the following table.
Key: Y - Supported; N - Not Supported; N/A - not applicable
| Feature | Supported? | Notes | ||
|---|---|---|---|---|
| Admin-Defined Functions | Y | |||
| Box Plots | Y |
|
||
| Custom SQL Queries | Y | If you need to access a BigQuery partition, explicitly include an alias for the built in partition column in your select clause, such as select *, _PARTITIONTIME as pt from projectId.datasetId.tableId. |
||
| Derived Fields (Row-Level Expressions) | Y | |||
| Distinct Counts | Y | Cloudera Impala connectors can receive only a single distinct count field in a query. | ||
| Fast Distinct Values | N/A | |||
| Group By Multiple Fields | Y | |||
| Group By Time | Y | |||
| Group By UNIX Time | Y | |||
| Histogram Floating Point Values | Y | |||
| Histograms | Y | |||
| Kerberos Authentication | Y |
|
||
| Last Value | Y | |||
| Live Mode and Playback | Y | |||
| Multivalued Fields | N/A |
|
||
| Nested Fields | N/A | |||
| Partitions | Y | |||
| Pushdown Joins for Fusion Data Sources | Y | |||
| Schemas | Y | |||
| Text Search | N/A | |||
| TLS | Y | |||
| User Delegation | Y | |||
| Wildcard Filters | Y | |||
| Wildcard Filters, Case-Insensitive Mode | Y | |||
| Wildcard Filters, Case-Sensitive Mode | Y | |||
The Cloudera Impala connector also supports Progress reporting. Progress reporting support allows the connector to report the progress of a running query. On the UI, this shows as Reading nn% in the upper left corner of a visual.
Impala Authentication
Support is provided for passing along credentials for users with access privileges to Impala source. Delegation allows for Impala queries to be issued with the privileges from a specified user. This is available in the Connection page and is set as the Do As User list. See Enable User Delegation and Apply User Delegation to a Connection.
Connect to Impala
When setting up an Impala connection, you need to provide the following.
-
Specify the JDBC URL. You can connect to your Impala data source using either simple user credentials authentication or Kerberos authentication with optional SSL encryption. Refer to Connecting to Impala on Kerberized CDH or Connecting to Impala with TLS (SSL) for more details on the configuration.
Symphony enables you to connect either to a single Impala node or to multiple nodes within a cluster. To connect to a single Impala node, specify a JDBC URL in the following format:
jdbc:hive2://<impala_host>:<port>/;auth=noSasl
To connect to multiple Impala nodes, specify the required JDBC URLs separated by commas. The URLs will be used in a round-robin fashion. Keep in mind that such a connection will be valid as long as there is at least one available node. If all the nodes can not be reached, then the connection won't be validated.
- If Impala authentication has been set up, provide a user name and password.
- To allow for Impala user delegation, select the appropriate custom user attribute from the Do As User drop-down list (set up by the Symphony supervisor or administrator). This basically allows Symphony to pass along credentials for the specified user with access rights to Impala. See Enable User Delegation and Apply User Delegation to a Connection.
- Select Validate. If successfully validated, the connection is saved.
Impala Table Settings
Time-based fields can be configured for partitioning in an Impala data source configuration using the Partition column on the Fields tab of the data source. The following options are available:
-
No (partitioning to be done)
-
Date - this option is available for the Time field type. If you select this option, the list of the partitioned columns will be displayed in the Configure column.
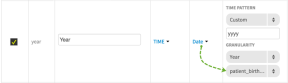
-
Function - If you select this option, the list of the partitioned columns and supported MURMUR3_HASH function will be displayed in the Configure column.

Numeric and time-based fields can be edited using the Fields tab:
- Numeric type Number - ability to select a default aggregation function
- Time fields - ability to define the default time pattern and granularity; if the time field provides granularities of hour, minute and second, then a time zone label may be applied.
Select the checkbox in the Distinct Count column for any fields if a distinct count is needed. For more information, see Work with Distinct Counts on Cloudera Impala.