Data Fusion Join Rules
This applies to: Visual Data Discovery
Data fusion joins are key to the success of your attempts to fuse data. So they must adhere to the rules described in this section.
You can explicitly specify the type of join that occurs for fusion: inner join, left outer join, or full outer join. Right outer joins are not supported. The join type can be selected for each pair of mapped fields in a join condition.
The following diagram depicts the relationship between the data entities you include in a Fusion data source and the join definitions and join conditions (mappings) you define in a Fusion data source.
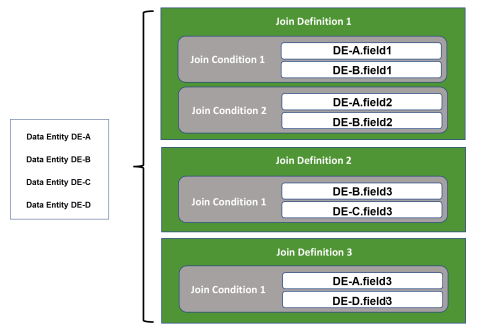
The following rules must be adhered to for data fusion joins:
-
Joins are processed in the order in which they are specified in the UI. This affects the resulting data and the performance of the join.
-
Only a single join definition is allowed between two data entites. The join definition can contain multiple join conditions (mappings), previously called forms. Each mapping must contain exactly two fields. The fields used in the mapping must be of the same type and should contain the same kind of data.
If there are more than two data entities in a Fusion data source definition, a single join definition can be specified for each unique combination of the included data entities. For example, if you have four data entities in your Fusion data source definition (sources A, B, C, and D), you can specify six join definitions, one each for these data entity combinations: A+B, A+C, A+D, B+C, B+D, and C+D.
-
Every data entity in a Fusion data source must be connected to at least one other data entity in the fused source. The data entities in a Fusion data source must be interconnected in some way.
For example, if you have four data entities (A, B, C, and D) in your Fusion data source definition, you cannot define only a join between sources A and B and a second join between entities C and D. In addition, all the data entities must be connected in some way to one of the others. So the following join sequence would be correct because every data entity is included: A+B, B+D, D+C. However, the following join sequence would be incorrect because data entity C is entirely omitted: A+B, A+D, B+D.
-
Each subsequent join in the Fusion data source configuration must use a data entity from one of the previously defined joins.
For example, if you have four data entities (A, B, C, and D) in your Fusion data source definition, if a join between entities A and B is the first join defined, the second join defined for the fused source must include either entity A or entity B and one of the other entities (C or D). So the following join sequence would be correct: A+B, B+D, D+C. However, the following join sequence would be incorrect because entity C and D are introduced before they have been linked to either entity A or entity B: A+B, D+C, B+D.
-
The data in mapped time fields must have the same granularity. Symphony assumes that the granularity of a time field correctly matches the granularity of its data. For example, if one time field contains data in days and another time field contains data in seconds, they cannot be joined. The only way to join these two time fields would be to modify the granularity of the underlying data in the data store.