Data Fusion Processing
This applies to: Visual Data Discovery
With data fusion, Symphony can perform Group By operations using fields that are available across tables. A variety of table structures residing in data repositories can be fused, including lookup tables, fact tables, star and snowflake schema structures. See Data Fusion Table Structures.
For example, if a table in one data repository contains the IDs and address information of sellers and another table in another data store contains IDs, events, and sales information for sellers, these disparate fields can be fused into one sellers table with the three fields joined and accessible (as shown below).
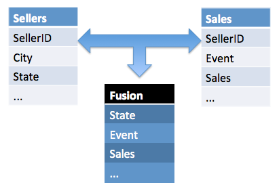
Using data fusion, you can create data entities to join disparate data repositories that are connected to Symphony. Multiple data entities (three or more) can be fused into a single Fusion data source.
To fuse these disparate data entities together, you must join matching fields from the different data sources on the Source Creation tab of the Fusion data source. This is the key step to data fusion and must adhere to specific rules.
Joins are usually performed in-memory. However, if a data connector supports pushdown joins and the data to be joined comes from the same data connection, Symphony pushes the join operation to the underlying data engines and allows those data stores to join the data instead. In addition, if the joins are inner joins and aggregate functions SUM, MIN, MAX, COUNT, DISTINCT COUNT, and aggregations are used in the data, the Symphony engine intelligently pushes the aggregate queries to the underlying data engines, thus reducing the amount of data that needs to be processed. This aggregate pushdown occurs when joining data from the same or from different data connections. For more information about optimizing joins in your Fusion data connections, see Optimize Joins.
Because most joins are performed in-memory, a configurable limit has been placed on the number of records that can be processed from each joined source. This limit is initially set at 1,000,000 records per joined data source and can be configured by your Symphony administrator or supervisor using the qe.zengine.edc.rows.limit property in the query-engine.properties file. See Manage the Symphony Query Engine. When this threshold is exceeded, no data is shown on the visuals containing the fused data and a message appears indicating that the threshold (maximum row number) is exceeded. If you find you are hitting this limit, use filters on the visual or dashboard to reduce the number of records processed and shown.
After you have joined the necessary fields from the data entities and saved your Fusion data source, you can visualize and explore the fused data in visuals and dashboards.